K-Means Clustering이란?
머신러닝에서 가장 대중적인 비지도학습 군집화 알고리즘 중 하나로, 군집의 중심점을 이동하며 전체 데이터를 K개의 Cluster로 묶는 방법입니다.
Cluster는 하나의 그룹, 집합, 군집 정도로 생각해 주시면 됩니다.

먼저, 데이터를 생성하기 위해 (0,0) (2,2) (-3,3) 주변으로 랜덤하게 100개의 포인트를 만들었습니다.
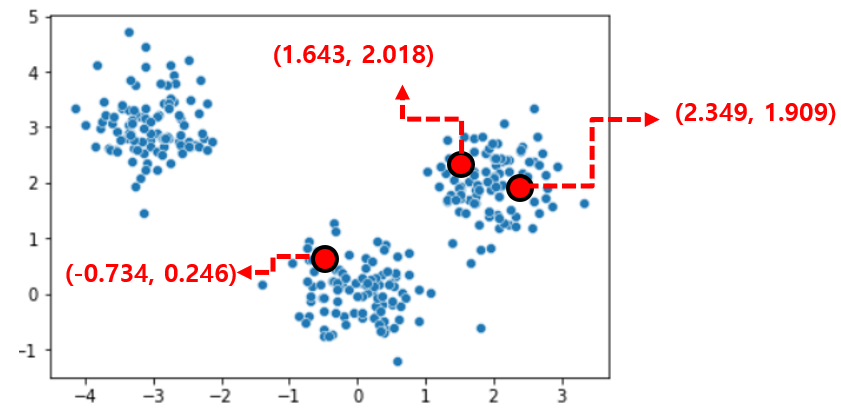
그다음, 이렇게 랜덤하게 세 개의 점으로 중심점들을 선언해 줍니다.
이후 모든 데이터에 대해 각 중심점과의 거리를 계산하고, 가장 가까운 중심점의 클러스터에 해당 데이터를 할당합니다.

그럼 이렇게 초기 군집이 형성이 됩니다.

좌측에 빨간 별로 표시한 데이터 하나를 예시로 보겠습니다.
빨간 점까지의 거리가 1.0979로 가장 짧아 검은색 클러스터에 포함된 것을 볼 수 있습니다.

이제 각 클러스터의 평균을 계산해서 중심점을 이동시킵니다.
* 때로는 평균 대신 클러스터의 중앙에 위치한 점을 중심으로 정하기도 합니다.
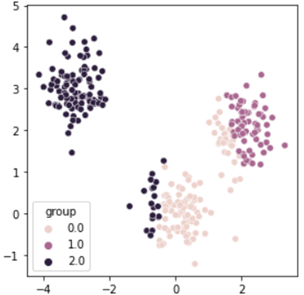
동일하게 모든 데이터와 중심점 사이의 거리를 계산한 후, 데이터를 가장 가까운 중심점이 속한 클러스터에 할당합니다.
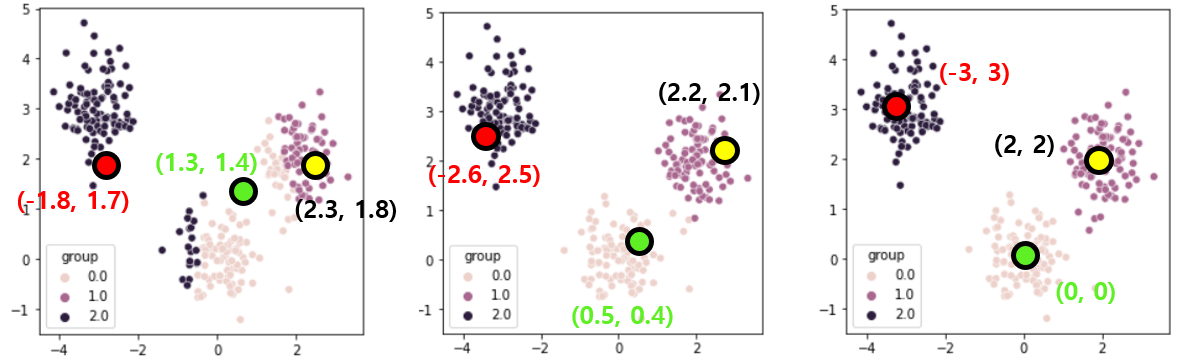
이때의 클러스터 중심점이 전체 데이터를 군집화하는 최종 중심점으로 간주됩니다.
클러스터 개수 K는 어떻게 정할까?
또 다른 데이터를 살펴봅시다.
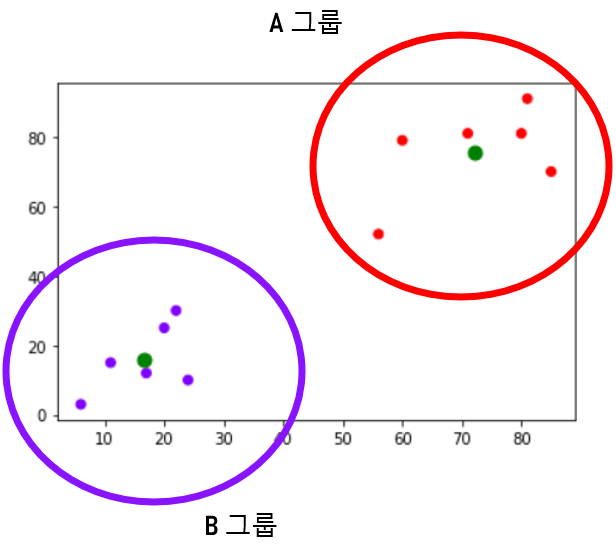
임의로 만든 12개의 점들에 대해 K=2 클러스터링을 진행하면, 위와 같은 클러스터를 얻을 수 있습니다.
K를 1 또는 3,4,5,6... 값으로 설정한다면, 원하는 결과는 아니더라도 어떤 결과라도 나오긴 할 겁니다.
이렇게 생성된 각 클러스터의 데이터와 중심점 간의 거리의 제곱합(SSE)을 그래프로 표현해 보겠습니다.

그래프를 보면, 클러스터 개수가 1일 때는 SSE 값이 매우 높았다가, 2일 때 급격히 감소하는 것을 볼 수 있습니다.
그 이후로는 차이가 크지 않지만, 값이 계속해서 줄어드는 것을 확인할 수 있습니다.
당연한 결과입니다. 클러스터의 개수가 많을수록 데이터 포인트들이 각자 더 가까운 중심점에 할당되기 때문이지요. 😗
보통 이렇게 모니터링하는 지표의 값이 뚝 떨어지는 지점의 인덱스를 K로 설정한답니다!
대학원 면접 준비 하다가 K-MEANS 알고리즘을 공부하던 도중 글을 쓰게 되었습니다 ㅎㅎ
학부 때 인공지능 과목에서 발표하려고 만들어뒀었는데 이렇게 사용하게 됐네요 😄
제 글이 여러분의 공부에 조금이나마 도움이 되었으면 좋겠습니다. 📚
궁금한 내용 댓글 남겨주시면 빠르게 답변해 드리도록 하겠습니다. 😍
'ML' 카테고리의 다른 글
| 핸즈온 머신러닝 3장 분류 연습문제 코드 (3) | 2024.07.14 |
|---|