
본 논문은 ICLR 2015에 게재된 논문입니다. (저자 소속: University of Oxford)
논문 링크: https://arxiv.org/pdf/1409.1556
1. VGGNet
VGGNet은 ILSVRC-2014에서 준우승을한 모델입니다.
2014년에 발표됐음에도 불구하고 현재까지도 정말 많은 모델들의 Backbone으로 쓰이는 아주 대단한 모델입니다.
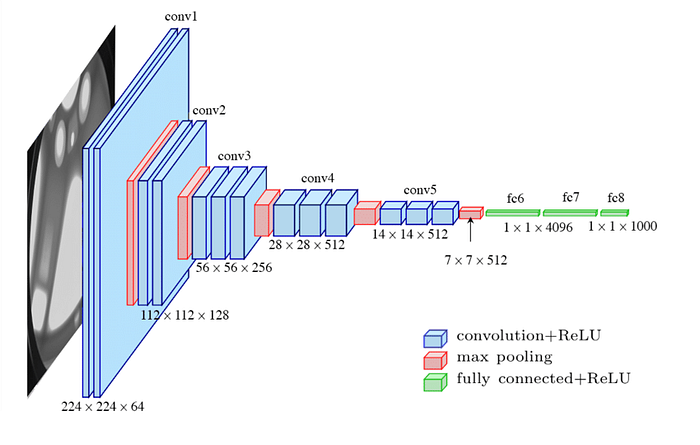
VGGNet 모델의 특징을 요약하자면 다음과 같습니다.
- Convolutional layer: 3x3 filter / stride 1 / pad 1
- Max-pooling layer: 2x2 window / stride 2
- Removal of LR
- VGG16(138M) & VGG19 (144M)
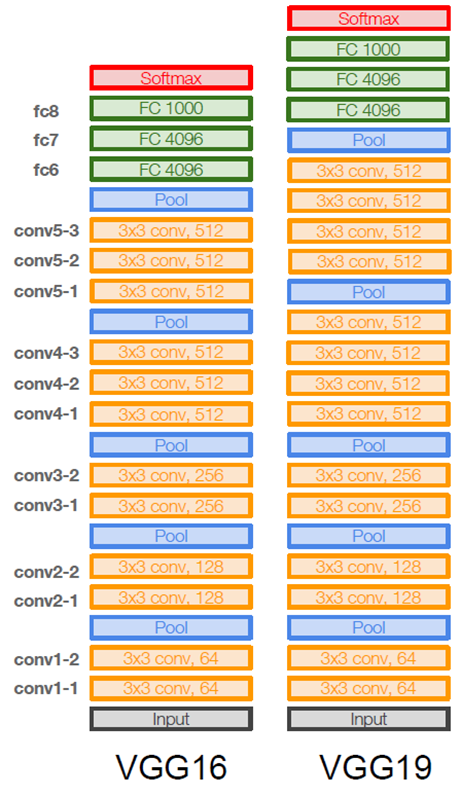
VGG16과 VGG19의 구조는 위와 같습니다.
2. Why 3x3 convolutions?
VGGNet의 가장 큰 특징은 3x3 Convolutional 레이어만 사용했다는 점입니다.
도대체 왜 필터 사이즈를 3x3 으로만 고정했을까요?
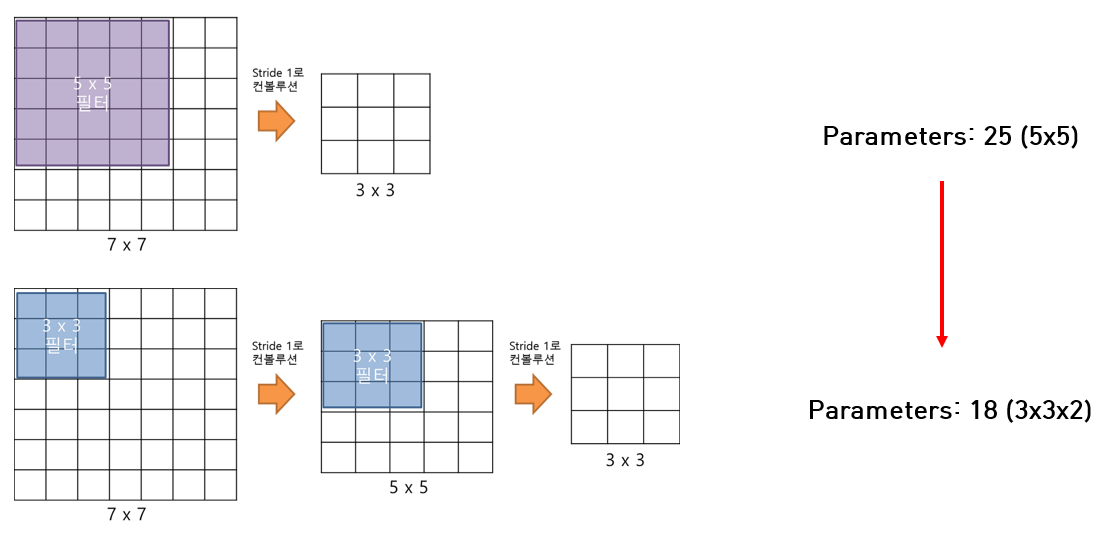
7x7 input에 Convolution 연산을 적용해 3x3 feature를 만든다고 가정해봅시다.
5x5 필터로 1회 연산을 수행하는 데 필요한 파라미터 개수는 25개입니다.
반면 3x3 필터로 2회 연산을 수행하는 데 필요한 파라미터 개수는 18개입니다.
두 연산은 같은 결과를 만들어내지만, 3x3 필터에서 파라미터 개수는 약 28% 줄어들었습니다.
3x3 filter를 사용하는 이유는 더 적은 파라미터로 더 넓은 receptive field를 포착하기 위함이다 라고 생각하시면 됩니다.
3. Architecture with Code
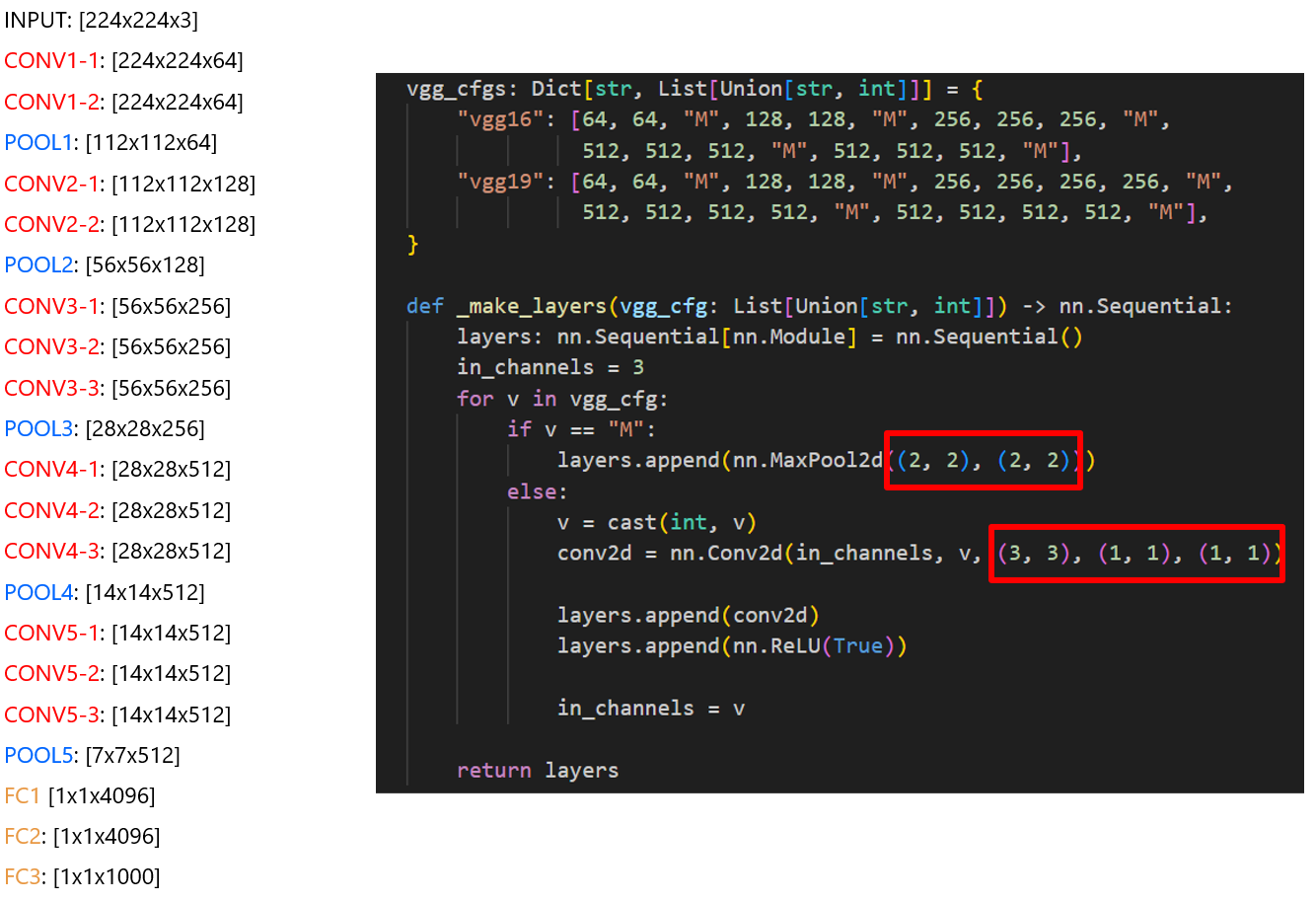
오른쪽 사진에 Max-pooling 레이어와 Convolutional 레이어가 어떻게 선언되었는지 표시해 놨습니다.
코드가 간단하니 시간날 때 구현 한번 해보시는 거 추천드립니다. 😊
다음 포스팅들에서도 유명한 Backbone 모델들에 대해 다룰 예정이니 참고 바랍니다!
저의 글이 언제나 여러분께 도움이 되길 바라겠습니다. 👍
궁금한 내용 댓글 남겨주시면 빠르게 답변해 드리도록 하겠습니다. 😍