
본 논문은 CVPR 2014에 게재된 논문입니다. (저자 소속: Microsoft Research)
논문 링크: https://arxiv.org/pdf/1512.03385
1. ResNet
ResNet은 ILSVRC-2015와 COCO-2015 우승 모델입니다.
논문에서는 Skip Connection 기법을 적용한 Residual Block을 기반으로, 이전 모델보다 더 깊은 네트워크인 ResNet을 제안합니다.

기존의 문제점: 네트워크의 깊이가 깊어질수록 underfitting 문제가 발생했다.
저자들의 아이디어: 성능이 좋은 얕은 네트워크(shallow network)에 층을 추가할 때, 이전 레이어의 입력을 출력에 더하면 최소한 얕은 네트워크만큼의 성능은 유지할 수 있어야 한다.
따라서 저자들은 위와 같은 구조의 ResNet 모델을 탄생시켰습니다.
그렇게 어려운 내용은 없으니 부담 없이 읽으시면 좋겠습니다.
2. Residual Block

Residual Block은 그림과 같이 이전 레이어의 입력 x를 현재 레이어의 출력 F(x)에 더해주는 모듈입니다.

H(x) = F(x) + x 라고 한다면, 학습은 H(x)가 x를 따르도록 진행됩니다.
⮕ Residual block에서 최적의 함수가 항등 함수라면, 즉 학습할 필요가 없다면, 이상적인 상황에서 F(x) = 0이 되어야 하기 때문입니다.
이 개념 덕분에 층이 깊어져도 입력 정보를 유지할 수 있어서 최소한 기존 네트워크보다 성능이 떨어지지 않는 구조가 됩니다.
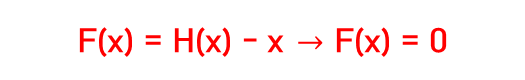
저자들은 H(x)가 x를 따르도록 만드는 것보다 Residual(잔차)가 0을 향하도록 학습시키는 것이 더 성능이 좋았다고 합니다.
Residual을 직접적으로 학습에 사용하기 때문에 Residual Learning이라 불립니다.
3. Removal of Pooling Layer

기존 네트워크들과의 차이점이 있다면 바로 max-pooling 레이어를 사용하지않는 것입니다.
그럼 어떻게 feature의 해상도를 줄였을까요?
빨간색 동그라미 친 부분을 보시면 /2 라고 써져 있습니다.
이것은 convolution filter의 stride 크기입니다.
저자들은 filter의 stride를 2로 설정해서 convolution 연산을 수행하며 자연스럽게 feature의 크기가 작아지도록 했습니다.
Max-pooling 레이어로 인한 정보 손실을 어느 정도 줄였기 때문에 좋은 성능이 나온 것 같습니다.
4. ResNet Variants

ResNet 논문에서 5개의 variants를 제안합니다.
보통 ResNet을 backbone으로 하는 모델들은 ResNet-50, 101, 152를 많이 쓰곤 하죠.
이렇게 레이어가 50개 이상인 모델들에 대해서는 연산량 감소를 위해 1x1 convolutions를 3x3 convolutions 뒤에 추가해 줬습니다.
아마 이 부분은 GoogLeNet의 Inception 모듈에 영감을 받은 구조가 아닐까 싶습니다.
[Backbone] GoogLeNet 모델 설명 Going Deeper with Convolutions (CVPR 2014)
본 논문은 CVPR 2014에 게재된 논문입니다. (저자 소속: Google)논문 링크: https://arxiv.org/abs/1409.4842 1. GoogLeNetGoogLeNet은 ILSVRC-2014에서 우승한 모델입니다.본 논문에서 Inception 모듈이란 것을 처음으로
happy-support.tistory.com
GoogLeNet에 대한 설명은 해당 포스팅에 잘 설명되어 있으니 참고 바랍니다. 😊
다음 포스팅들에서는 유명한 Vision Language 모델의 Backbone인 ViT에 대해 다룰 예정입니다!
저의 글이 언제나 여러분께 도움이 되길 바라겠습니다. 👍
궁금한 내용 댓글 남겨주시면 빠르게 답변해 드리도록 하겠습니다. 😍